RAG Çağının Sonu mu Geliyor?
Araştırmacılar, Kusursuz Görünen Modellerin Gerçek Bilgiyle İmtihanını Gözler Önüne Serdi
Bilgiyle desteklenen yapay zeka yanıtları artık kimseyi kandıramıyor. Cornell, EPFL ve Google DeepMind araştırmacıları tarafından yayımlanan yeni bir çalışma; Bilgiyle Zenginleştirilmiş Yanıtlama(Retrieval Augmented Generation) sistemlerinin, ellerine doğru ve yeterli bağlam verildiğinde bile gerçek dışı bilgiler (halüsinasyon) üretmeye devam ettiğini ortaya koydu. Dahası bu hatalar dışarıdan bakıldığında neredeyse ayırt edilemiyor.
Araştırma; bağlam verilmiş olmasına rağmen modelin hatalı veya uydurma yanıtlar üretebildiğini, üstelik bu yanıtların kullanıcıya “doğruymuş gibi” geldiğini gösteriyor. Bu da RAG sistemlerini sadece teknik açıdan değil, etik ve güvenlik açısından da sorgulanan bir konuma getiriyor.
📌 “Context enough” devri kapanıyor olabilir.
Bugüne kadar RAG mimarileri, büyük dil modellerinin güvenilirliğini arttırmanın yolu olarak görülüyordu. Ancak bu çalışma, modellerin yalnızca bilgiye erişiminin yeterli olmadığını, aynı zamanda o bilgiyi doğru yorumlama ve yansıtma kabiliyetinin de geliştirilmesi gerektiğini vurguluyor.
Araştırmanın çarpıcı bulgularından biri de şu: Halüsinasyonlu çıktılar, kullanıcı testlerinde genellikle “başarılı” olarak puanlandı. Yani model yanlış bile söylese yeterince ikna edici olduğu sürece fark edilmiyor.
🔍 Gelecek Senaryosu: RAG 2.0 mı Yoksa Alternatif Paradigmalar mı?
Bu gelişme, model geliştiriciler için önemli bir uyarı niteliğinde. Geliştiricilerin artık sadece bilgiye erişen değil, bilgiyi doğru biçimde işleyebilen ve gerçeklikten sapma riskini izleyebilen sistemler tasarlaması gerekiyor. Aksi takdirde kullanıcı güveni geri dönüşü olmayan şekilde sarsılabilir.
Şu an için hâlâ güçlü bir araç olan RAG modelleri, belki de yeni bir versiyonun eşiğinde. Halüsinasyona karşı bağlamın değil, anlamın ve içsel kontrol mekanizmalarının öne çıktığı bir gelecek bizi bekliyor olabilir.
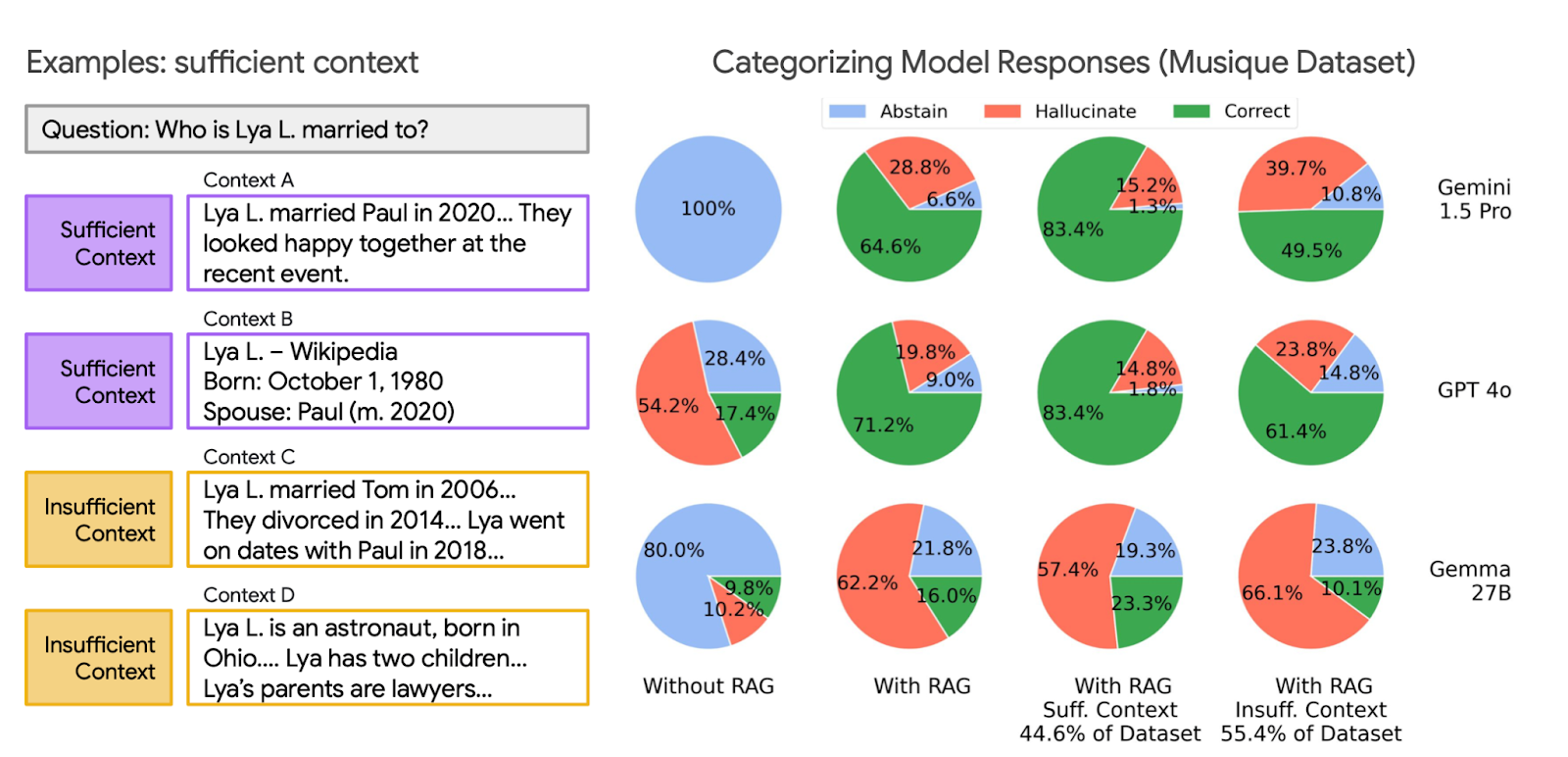
Şekil 1: RAG sistemlerinde bağlam yeterliliği ve model yanıtlarının analizi.
Sol tarafta yeterli bağlama sahip örnekler, sağda ise Musique veri seti üzerinde model yanıtlarının doğruluk ve halüsinasyon dağılımı yer almakta. RAG kullanımı doğruluk oranını artırsa da, bağlam yetersizliğinden bağımsız olarak halüsinasyon üretme eğilimi artmakta. Ayrıca, veri setindeki örneklerin büyük bölümü (%55,4) yeterli bağlamdan yoksunmuş.
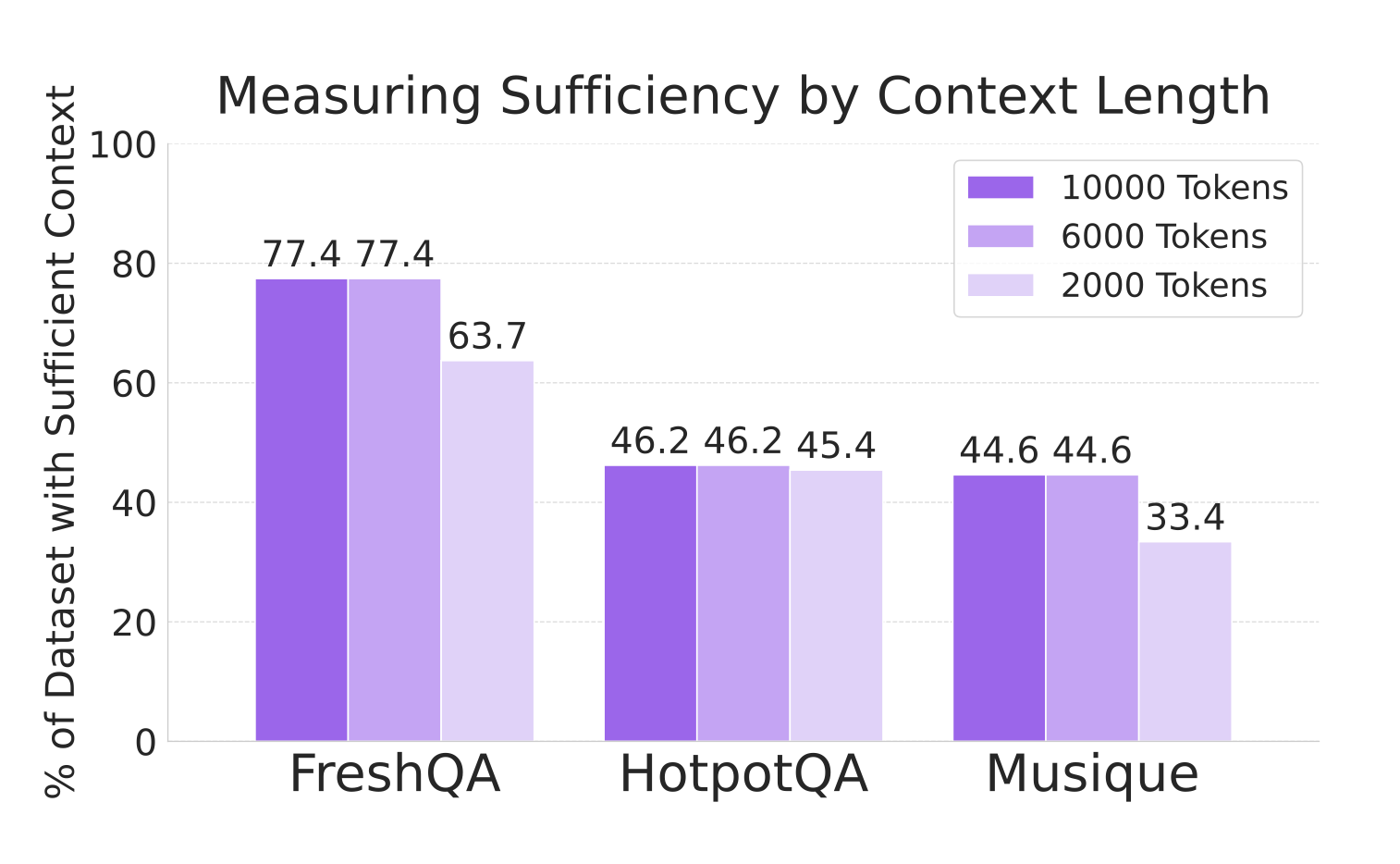
Şekil 2: Farklı bağlam uzunluklarında veri setlerindeki bağlam yeterliliği oranları.
FreshQA, yanıtları destekleyen özenle seçilmiş kaynaklara sahip olduğu için yüksek bağlam yeterliliği göstermekte. HotPotQA ve Musique ise özellikle kısa bağlam uzunluklarında (örneğin 2000 token) daha düşük oranlara sahip. Çalışmanın geri kalanında 6000 token’lık bağlam uzunluğu tercih edilmiş.
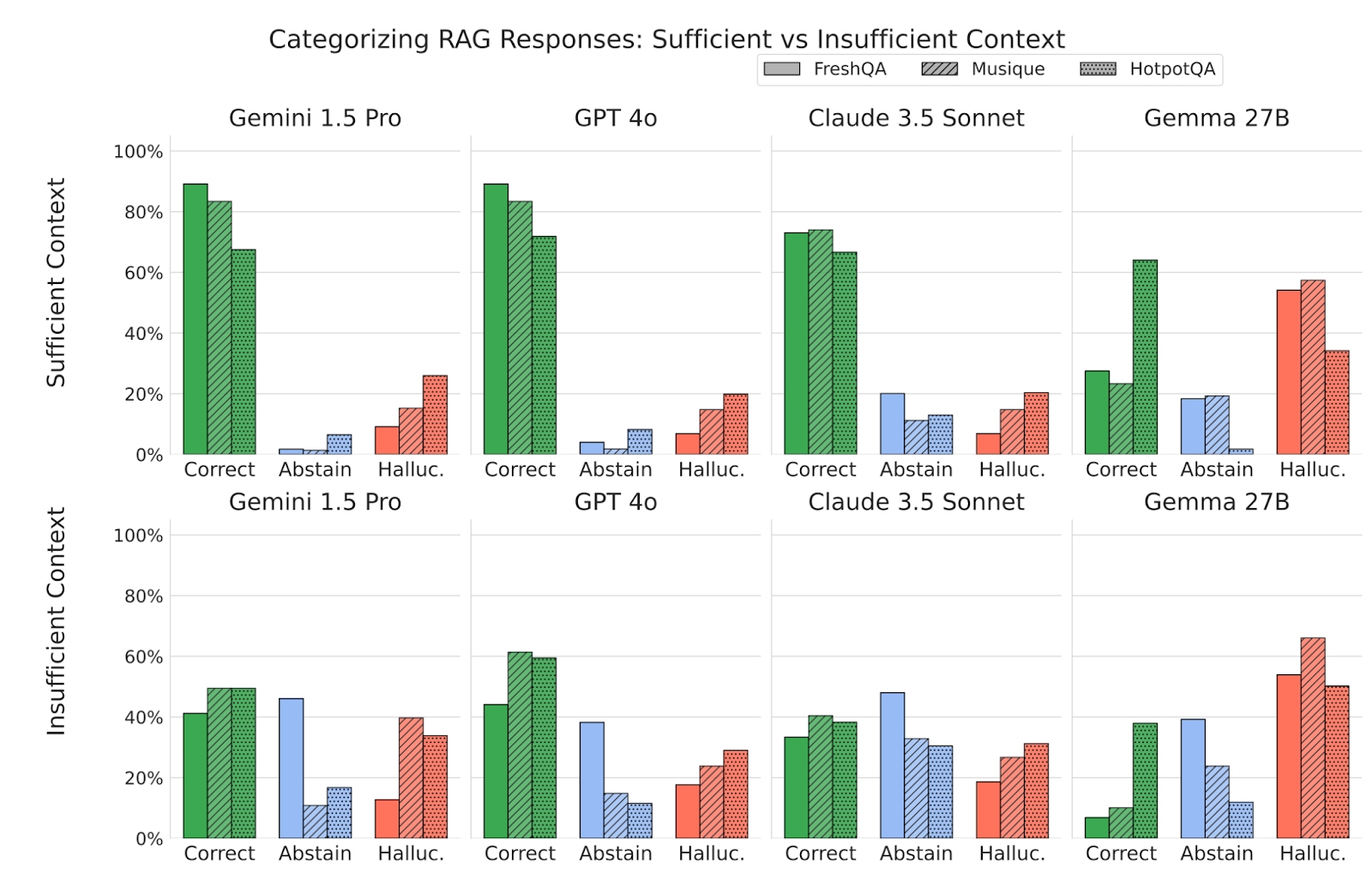
Şekil 3: Bağlam yeterliliğine göre ayrıştırılmış model performansı.
Yeterli bağlam sağlandığında modellerin doğruluk oranı yükselmekte; ancak bağlam yetersiz olduğunda da önemli oranda doğru yanıt üretilebiliyor. Buna rağmen, tüm modeller, özellikle de Gemma 27B gibi daha küçük boyutlu olanlar, bağlam yetersizliğinde halüsinasyon üretmeye daha yatkın oluyor.
Joren, H., Zhang, J., Ferng, C. S., Juan, D. C., Taly, A., & Rashtchian, C. (2024). Sufficient Context: A New Lens on Retrieval Augmented Generation Systems. arXiv preprint arXiv:2411.06037.
Teoman Yiğit Duman

Comments
Post a Comment